microbiomedataset A tidyverse-style framework for organizing and processing microbiome data
Abstract
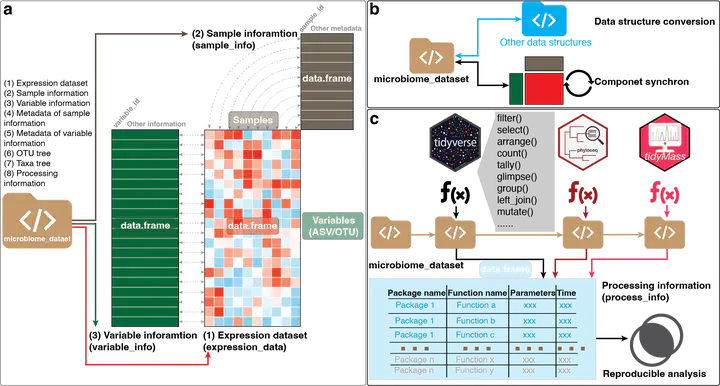
Microbial communities exert a substantial influence on human health and have been unequivocally associated with a spectrum of human maladies, encompassing conditions such as anxiety1, depression2, hypertension3, cardiovascular diseases4, obesity4,5, diabetes6, inflammatory bowel disease7, and cancer8,9. This intricate interplay between microbiota community structures and host pathophysiology has kindled substantial interest and spurred active research endeavors across various scientific domains. Despite significant strides in sequencing technologies, which have unveiled the vast diversity of microbial populations across diverse ecosystems, the analysis of microbiome data remains a formidable challenge. The complexity inherent in such data, compounded by the absence of standardized data processing and analysis workflows, continues to pose substantial hurdles. The tidyverse paradigm, comprised of a suite of R packages meticulously crafted to facilitate efficient data manipulation and visualization, has garnered considerable acclaim within the data science community10. Its appeal stems from its innate simplicity and efficacy in organizing and processing data10. In recent times, a plethora of tools have been devised to address distinct omics data processing and analysis needs, including notable initiatives such as the tidymass project11, tidyomics project12, tidymicro13, and MicrobiotaProcess13,14. However, a conspicuous gap persists in the form of a standardized, tidyverse-based package for seamless and rigorous microbiome data processing and analysis. To address this burgeoning demand for standardized and reproducible microbiome data analysis, we introduce microbiomedataset, an R package that embraces the tidyverse ethos to furnish a structured framework for the organization and processing of microbiome data. Microbiomedataset offers a comprehensive, customizable solution for the management, structuring, and processing of microbiome data. Importantly, this package seamlessly integrates with established bioinformatics tools, facilitating its incorporation into existing analytical pipelines11,13,14,15. Within this manuscript, we proffer an in-depth overview of the microbiomedataset package, elucidating its multifarious functionalities. Moreover, we substantiate its utility through illustrative case studies employing a publicly available microbiome dataset. It is imperative to underscore that microbiomedataset constitutes an integral component of the larger tidymicrobiome project, accessible via www.tidymicrobiome.org. Tidymicrobiome epitomizes an ecosystem of R packages that share a coherent design philosophy, grammar, and data structure, collectively engendering a robust, reproducible, and object-oriented computational framework. This project’s development has been guided by several key tenets (1) Cross-platform compatibility, (2) Uniformity, shareability, traceability, and reproducibility, and (3) Flexibility and extensibility. We further expound upon the advantages inherent in adopting a tidyverse-style framework for microbiome data analysis, underscoring the pronounced benefits in terms of standardization and reproducibility that microbiomedataset offers. In sum, microbiomedataset furnishes an accessible and efficient avenue for microbiome data analysis, catering to both neophyte and seasoned R users alike.
Xiaotao Shen
Nanyang Assistant Professor
Metabolomics, Multi-omics, Bioinformatics, Systems Biology.
{kind=link}