Normalization and integration of large-scale metabolomics data using support vector regression
Abstract
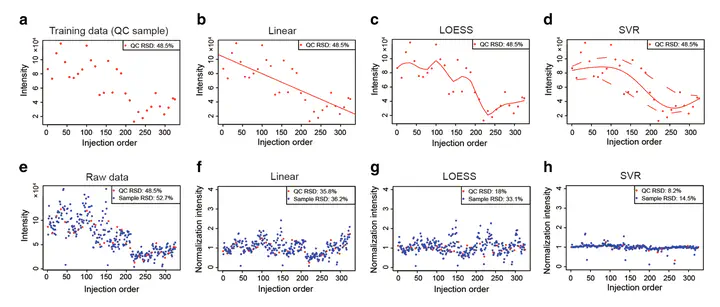
Untargeted metabolomics studies for biomarker discovery often have hundreds to thousands of human samples. Data acquisition of large-scale samples has to be divided into several batches and may span from months to as long as several years. The signal drift of metabolites during data acquisition (intra- and inter-batch) is unavoidable and is a major confounding factor for large-scale metabolomics studies. We aim to develop a data normalization method to reduce unwanted variations and integrate multiple batches in large-scale metabolomics studies prior to statistical analyses. We developed a machine learning algorithm-based method, support vector regression (SVR), for large-scale metabolomics data normalization and integration. An R package named MetNormalizer was …
Xiaotao Shen
Nanyang Assistant Professor
Metabolomics, Multi-omics, Bioinformatics, Systems Biology.
{kind=link}